

Zig for C programmers - async/await - Part 1
Basic C implementation of coroutines


Table of contents
Introduction
One of the things that grabbed my attention the most while I was having a first look at the features provided by the Zig language was the async/await keywords.
const net = @import("std").net;
pub const io_mode = .evented;
pub fn main() !void {
const addr = try net.Address.parseIp("127.0.0.1", 7000);
var sendFrame = async send_message(addr);
// ... do something else while
// the message is being sent ...
try await sendFrame;
}
// Note how the function definition doesn't require any static
// `async` marking. The compiler can deduce when a function is
// async based on its usage of `await`.
fn send_message(addr: net.Address) !void {
// We could also delay `await`ing for the connection
// to be established, if we had something else we
// wanted to do in the meantime.
var socket = try net.tcpConnectToAddress(addr);
defer socket.close();
// Using both await and async in the same statement
// is unnecessary and non-idiomatic, but it shows
// what's happening behind the scenes when `io_mode`
// is `.evented`.
_ = try await async socket.write("Hello World!\n");
}
I had already seen them in other languages like C#, Python, Dart, Rust, etc. But as they never felt too appealing to me for writing server side code, I was not paying too much attention to that programming pattern. I prefer the concept of goroutines introduced by Golang much more for handling server requests, agreeing with what Loris Cro says on his awesome article about async/await. However, after digging a bit deeper into this subject, it is clear to me that using this pattern for writing client code is very convenient. You can express the logic of your application in a much clearer way. This is related to the infamous "callback hell" very well known in the javascript world. But once I understood the pros of this feature, I wanted to know how it works under the hood. The first time you approach this programming pattern, it is not completely straightforward to understand how it works, because it involves several complex concepts: coroutines, event loops, thread pools, etc. So I decided to develop a toy implementation of async/await in C. As this language does not provide any of those concepts out of the box, building each one of them from scratch will allow you to gather the knowledge required to truly understand how async/await works.
Coroutines
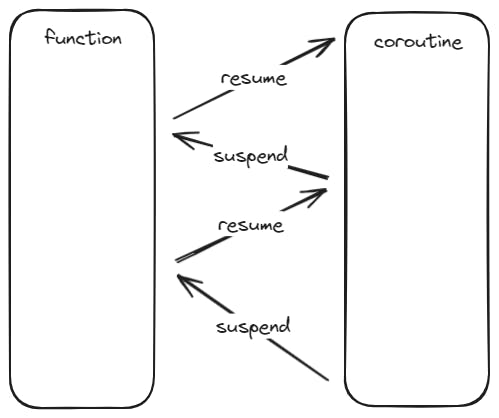
When you start looking for a definition of coroutines, you usually find resources that define them as "computer program components that generalize subroutines for non-preemptive multitasking by allowing execution to be suspended and resumed. They are also known as cooperative multitasking or cooperative threading." Easy, right? Coroutines are just resumable functions. Period. It just means that the execution of a coroutine can be suspended. At that point, the execution flow will come back to the caller function. And if that function resumes the coroutine, the execution flow will go back to the coroutine code where it was suspended.
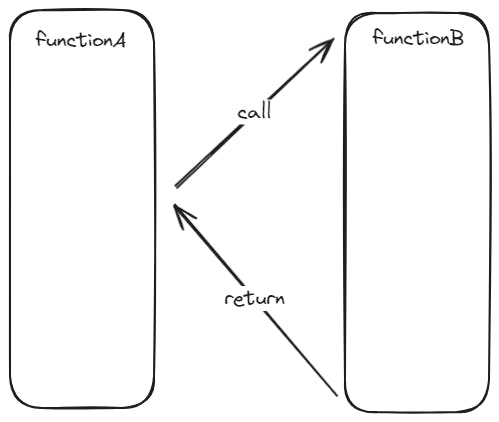
How is this possible? When we execute a subroutine, we create a new function stack to store function parameters, local variables and result value. Once the function returns, its function stack is destroyed.
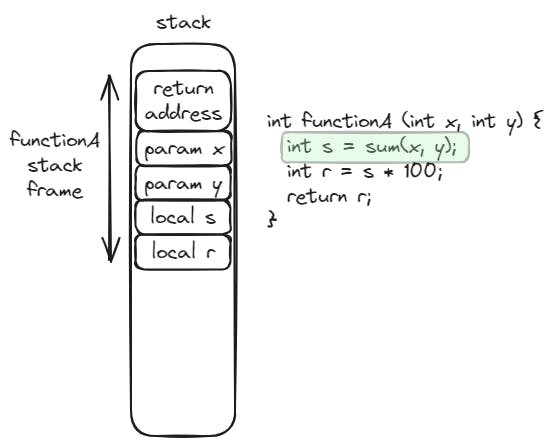


However, in the case of coroutines, as they can be suspended and resumed, we need to keep track of the caller and callee function stacks. That way we can switch between them when we suspend or resume the coroutine.
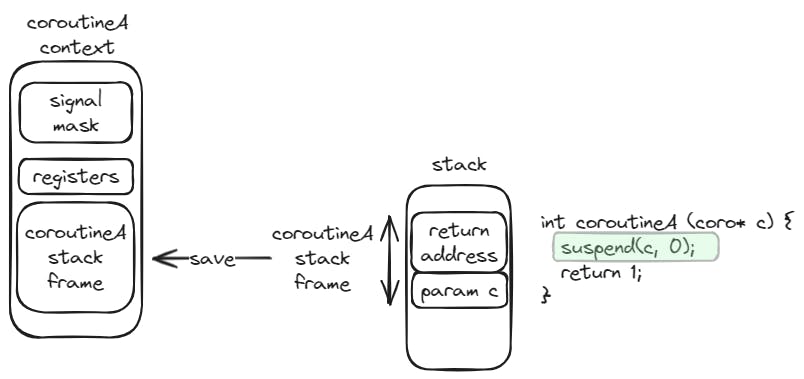
We can create a simple implementation of coroutines in C using the ucontext (user context) module. It provides you with the functions to create a user context (getcontext and makecontext), which includes the following information:
the contents of the calling thread's machine registers
the signal mask
the current execution stack
And the function to switch contexts (swapcontext). Keeping a reference to the caller user context and the callee user context on the coroutine object, we can switch back and forth between them when we suspend or resume the coroutine.
The suspend function of a coroutine is also referred to as yield, because it can produce an intermediate value that can be received on the caller function. So the coroutine can provide values to the caller function every time it suspends. But I prefer to stick to the suspend name, as it is clearer and it also matches the keyword used by the Zig language.
When we create a coroutine, we allocate the memory required for storing the context of the coroutine function.

The resume function will save the caller function context, and swap it with the context of the coroutine function. The execution flow will continue at the point of the coroutine function where it was suspended. If the coroutine function has not yet been suspended yet, the execution flow will continue at the starting point of the coroutine function.
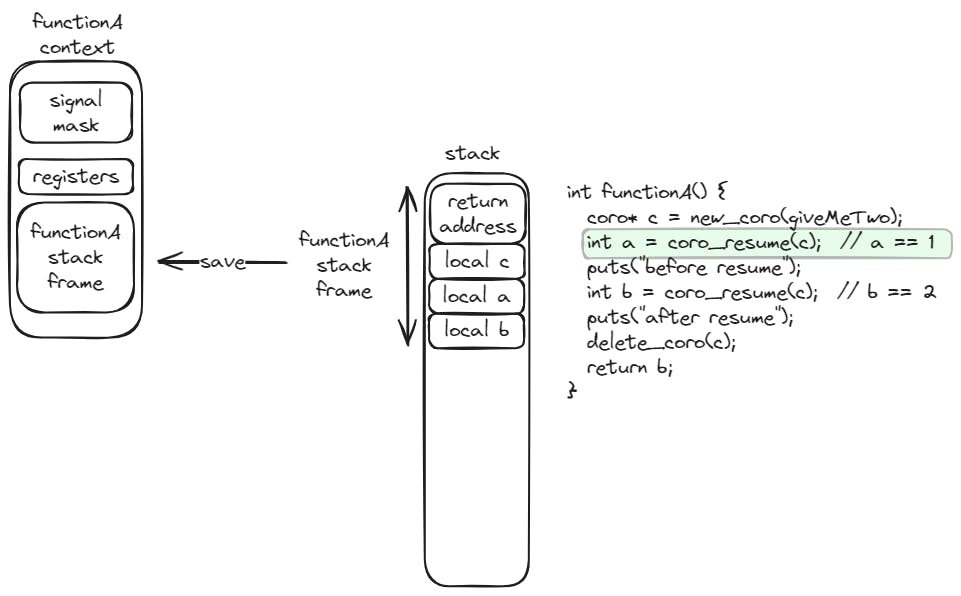
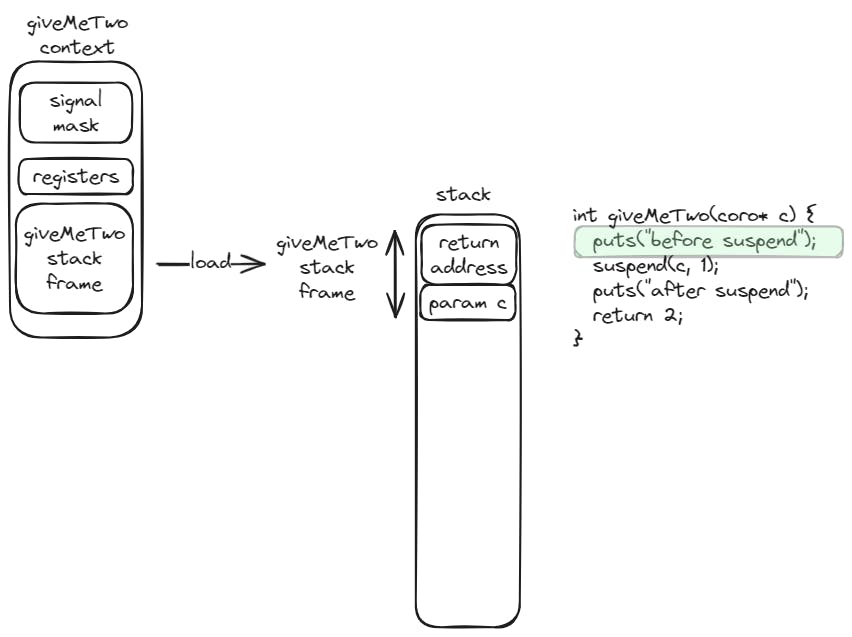
Similarly, the suspend function will save the callee function (coroutine function) context, and swap it with the context of the caller function. The execution flow will continue at the point of the caller function where it resumed the coroutine function.
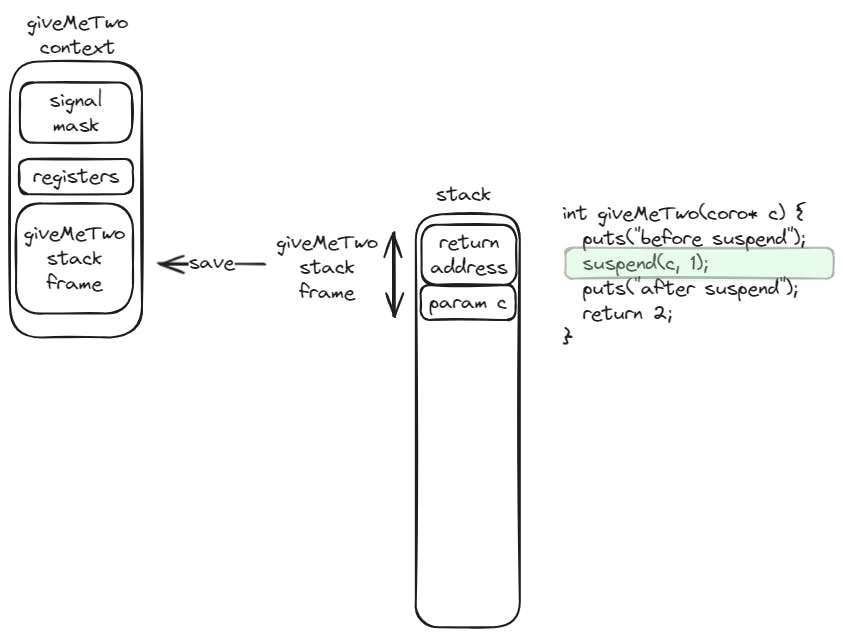

Implementation
Let's code a basic implementation of a coroutine that is able to generate integer values.
#include <stdio.h>
#include <stdlib.h>
#include <stdbool.h>
#include <ucontext.h>
typedef struct Coroutine Coroutine;
typedef int (*CoroutineFn)(Coroutine*);
struct Coroutine {
CoroutineFn fn;
ucontext_t caller_ctx;
ucontext_t callee_ctx;
int yield_value;
bool finished;
};
Coroutine* new_Coroutine(CoroutineFn fn);
int Coroutine_resume(Coroutine* c);
void Coroutine_suspend(Coroutine* c, int value);
void delete_Coroutine(Coroutine* c);
static
const int default_stack_size = 4096;
static
void Coroutine_entry_point(Coroutine* c) {
int result = c->fn(c);
c->finished = true;
Coroutine_suspend(c, result);
}
Coroutine* new_Coroutine(CoroutineFn fn) {
Coroutine* c = (Coroutine*)calloc(1, sizeof(Coroutine));
c->fn = fn;
getcontext(&c->callee_ctx);
c->callee_ctx.uc_stack.ss_sp = calloc(1, default_stack_size);
c->callee_ctx.uc_stack.ss_size = default_stack_size;
c->callee_ctx.uc_link = 0;
makecontext(&c->callee_ctx, (void (*)())Coroutine_entry_point, 1, c);
return c;
}
int Coroutine_resume(Coroutine* c) {
if (c->finished) return -1;
swapcontext(&c->caller_ctx, &c->callee_ctx);
return c->yield_value;
}
void Coroutine_suspend(Coroutine* c, int value) {
c->yield_value = value;
swapcontext(&c->callee_ctx, &c->caller_ctx);
}
void delete_Coroutine(Coroutine* c) {
free(c->callee_ctx.uc_stack.ss_sp);
free(c);
}
int giveMeTwo(Coroutine* c) {
printf("[%s] suspend 1\n", __func__);
Coroutine_suspend(c, 1);
printf("[%s] after suspend\n", __func__);
return 2;
}
int main() {
Coroutine* c = new_Coroutine(giveMeTwo);
{
printf("[%s] resume\n", __func__);
int a = Coroutine_resume(c); // a == 1
printf("[%s] after resume a: %d\n", __func__, a);
printf("[%s] resume\n", __func__);
int b = Coroutine_resume(c); // b == 2
printf("[%s] after resume b: %d\n", __func__, b);
}
delete_Coroutine(c);
return 0;
}
The output of this example is as follows:
[main] resume
[giveMeTwo] suspend 1
[main] after resume a: 1
[main] resume
[giveMeTwo] after suspend
[main] after resume b: 2
So far so good. But we want to use coroutines for providing asynchronous functionality. This means that we need to relate them to threads somehow. But how can we mix this functionality with threads? We can use suspend and resume calls as synchronization points between multiple threads communicating through safe-thread queues. Not bad, right? We will continue our investigation about how async/await works by implementing a basic thread pool on the Part2 of this series. Stay tunned!