

Zig for C programmers - async/await - Part 2
Basic C implementation of a Thread Pool


Table of contents
Now that we have our coroutines implementation ready, let's move on to the next concept required for the implementation of async/await, thread pools.
A thread pool is a concurrent programming concept that involves managing a group or pool of pre-initialized threads to efficiently execute tasks. The architecture of a thread pool typically consists of the following components:
Thread Pool Queue: The queue holds the tasks or jobs that need to be executed by the thread pool. When a task arrives, it is added to the queue, and an available thread from the pool picks it up for execution. This queue helps in managing the order of task execution and prevents overloading the system with too many active threads simultaneously.
Worker Threads: Worker threads are pre-initialized threads kept in the pool, ready to execute tasks. They continuously check the task queue for new tasks to execute. Once a task is obtained from the queue, a worker thread processes it and becomes available for the next task.
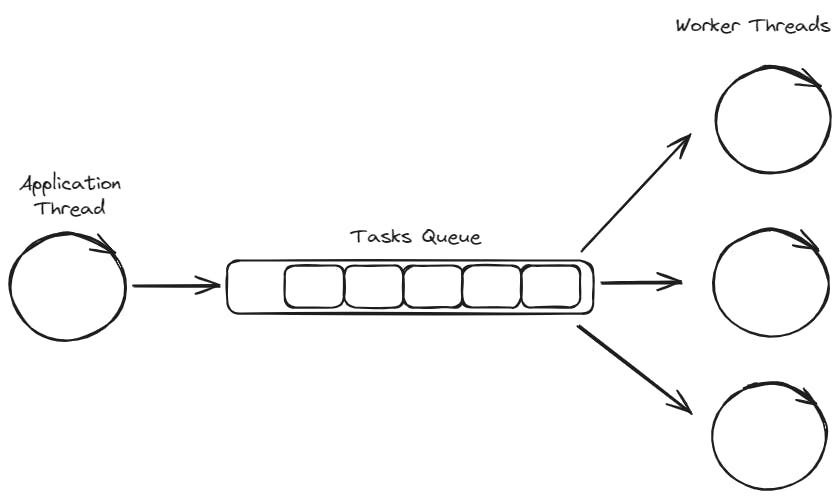
As many threads will be accessing the task queue in parallel for new tasks, we need to implement a mechanism that avoids data races. We will do that by implementing a thread safe queue. But first, we need to start with the implementation of a basic queue.
Queue
A queue is a fundamental data structure in computer science that follows the First-In-First-Out (FIFO) principle. In a queue, elements are added to the rear (enqueue) and removed from the front (dequeue). Imagine it as a line of people waiting for a service—those who arrive first are served first.
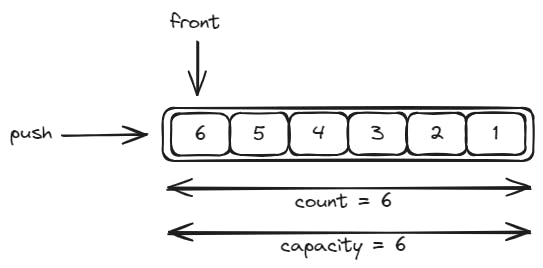
A circular queue, also known as a ring buffer, is a variation of the basic queue data structure with a circular arrangement of elements in a fixed-size array. Unlike a traditional queue, where elements are added at one end and removed from the other, a circular queue reuses the space in the array, creating a circular pattern.
For example, if we have a queue of six elements of capacity, we push six items and then we pop out three of them, we'll end up having a queue with the following status:
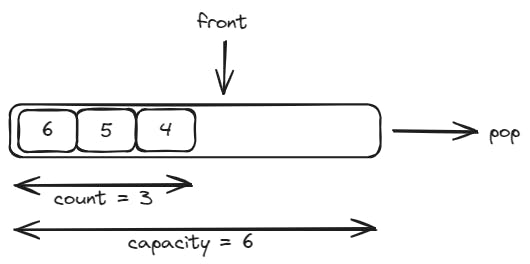
If after that we push three more items into the queue, its status will be the following:
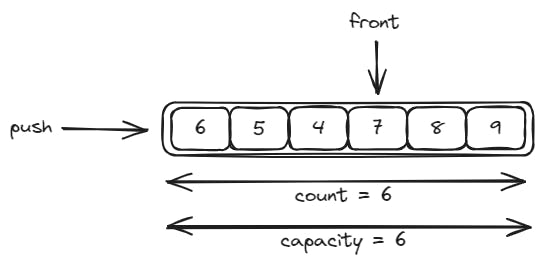
We will use a basic implementation of a circular queue as baseline for a thread safe queue.
typedef struct Queue {
size_t item_size;
size_t front;
size_t capacity;
size_t count;
void* items;
} Queue;
Queue* new_Queue(size_t item_size, size_t capacity) {
if (capacity <= 0) {
return NULL;
}
Queue* q = calloc(1, sizeof(Queue));
q->item_size = item_size;
q->capacity = capacity;
q->items = calloc(capacity, item_size);
return q;
}
void delete_Queue(Queue* q) {
free(q->items);
free(q);
}
bool Queue_push(Queue* q, void* item) {
if (q->count == q->capacity) {
return false;
}
char* items = (char*)q->items;
size_t index = (q->front + q->count) % q->capacity;
char* dst = &items[index * q->item_size];
memcpy(dst, item, q->item_size);
q->count++;
return true;
}
bool Queue_pop(Queue* q, void* item) {
if (q->count == 0) {
return false;
}
char* items = (char*)q->items;
size_t index = q->front;
char* src = &items[index * q->item_size];
memcpy(item, src, q->item_size);
q->count--;
q->front = (q->front + 1) % q->capacity;
return true;
}
Thread Safe Queue
A thread-safe queue is a data structure designed to be used in concurrent or multi-threaded environments where multiple threads may simultaneously access and modify the queue. The primary goal of a thread-safe queue is to ensure that operations such as enqueue (insertion) and dequeue (removal) can be performed safely without leading to race conditions, data corruption, or other synchronization issues. In our case, the main thread will be accessing the queue for pushing new tasks. Whereas the worker threads will access the queue for popping queued tasks.
Condition variables are synchronization primitives used in concurrent programming to coordinate the execution of threads. We will use them together with mutexes to implement a thread-safe queue. When the client tries to push a new item into the queue but there is no room available, the client will wait on a condition variable until it gets notified about the availability of a new slot for pushing the item. But to avoid keeping the client stuck in that call in case there is no room available in the queue for a long time, we will use a timed condition variable. So that the client can wake up after each second to allow them to decide if they want to keep waiting or not. The same happens on the other end of the queue. We will use a timed condition variable for popping out items from the queue.
typedef struct SafeQueue {
pthread_mutex_t mutex;
pthread_cond_t pop_cv;
pthread_cond_t push_cv;
Queue* queue;
} SafeQueue;
SafeQueue* new_SafeQueue(size_t item_size, size_t capacity) {
SafeQueue* q = calloc(1, sizeof(SafeQueue));
pthread_mutex_init(&q->mutex, NULL);
pthread_cond_init(&q->pop_cv, NULL);
pthread_cond_init(&q->push_cv, NULL);
q->queue = new_Queue(item_size, capacity);
return q;
}
void delete_SafeQueue(SafeQueue* q) {
delete_Queue(q->queue);
pthread_cond_destroy(&q->push_cv);
pthread_cond_destroy(&q->pop_cv);
pthread_mutex_destroy(&q->mutex);
free(q);
}
struct timespec get_timeout() {
struct timespec result;
clock_gettime(CLOCK_REALTIME, &result);
result.tv_sec += 1;
return result;
}
bool SafeQueue_push(SafeQueue* q, void* item) {
bool result = false;
pthread_mutex_lock(&q->mutex);
{
result = Queue_push(q->queue, item);
if (!result) {
struct timespec timeout = get_timeout();
pthread_cond_timedwait(&q->push_cv, &q->mutex, &timeout);
}
else {
pthread_cond_signal(&q->pop_cv);
}
}
pthread_mutex_unlock(&q->mutex);
return result;
}
bool SafeQueue_pop(SafeQueue* q, void* item) {
bool result = false;
pthread_mutex_lock(&q->mutex);
{
result = Queue_pop(q->queue, item);
if (!result) {
struct timespec timeout = get_timeout();
pthread_cond_timedwait(&q->pop_cv, &q->mutex, &timeout);
}
else {
pthread_cond_signal(&q->push_cv);
}
}
pthread_mutex_unlock(&q->mutex);
return result;
}
Atomic Bool
In order to stop the worker threads from the thread pool, we need a mechanism that allow us to notify them without running into race conditions. We will be using an atomic Boolean variable for that. But as C does not have support for atomic values, we will implement one from scratch.
An atomic bool is a type of variable in concurrent programming that supports atomic (indivisible) operations. We will use an atomic bool to signal to the threads in the pool that they should stop their execution.
typedef struct AtomicBool {
pthread_mutex_t mutex;
bool value;
} AtomicBool;
AtomicBool* new_AtomicBool() {
AtomicBool* b = calloc(1, sizeof(AtomicBool));
pthread_mutex_init(&b->mutex, NULL);
return b;
}
void delete_AtomicBool(AtomicBool* b) {
pthread_mutex_destroy(&b->mutex);
free(b);
}
bool AtomicBool_get(AtomicBool* b) {
bool result = false;
pthread_mutex_lock(&b->mutex);
{
result = b->value;
}
pthread_mutex_unlock(&b->mutex);
return result;
}
void AtomicBool_set(AtomicBool* b, bool value) {
pthread_mutex_lock(&b->mutex);
{
b->value = value;
}
pthread_mutex_unlock(&b->mutex);
}
Thread Pool
Now that we have all the components ready, we put them all together to implement a basic version of a thread pool.
static
const int NUM_THREADS = 4;
static
const int QUEUE_SIZE = 10;
typedef struct ThreadPool {
SafeQueue* queue;
pthread_t* threads;
size_t nthreads;
AtomicBool* running;
} ThreadPool;
void* ThreadPool_run(void* arg) {
ThreadPool* p = (ThreadPool*) arg;
while (AtomicBool_get(p->running)) {
Task task;
if (SafeQueue_pop(p->queue, &task)) {
task.cb(task.data);
}
}
return NULL;
}
void ThreadPool_start(ThreadPool* p) {
AtomicBool_set(p->running, true);
for (int i=0; i<p->nthreads; ++i) {
pthread_create(&p->threads[i], NULL, ThreadPool_run, p);
}
}
ThreadPool* new_ThreadPool() {
ThreadPool* p = calloc(1, sizeof(ThreadPool));
p->nthreads = NUM_THREADS;
p->queue = new_SafeQueue(sizeof(Task), QUEUE_SIZE);
p->threads = calloc(p->nthreads, sizeof(pthread_t));
p->running = new_AtomicBool();
ThreadPool_start(p);
return p;
}
void delete_ThreadPool(ThreadPool* p) {
AtomicBool_set(p->running, false);
for (int i=0; i<p->nthreads; ++i) {
pthread_join(p->threads[i], NULL);
}
free(p->threads);
delete_SafeQueue(p->queue);
delete_AtomicBool(p->running);
free(p);
}
void ThreadPool_submit(ThreadPool* p, Task task) {
while(!SafeQueue_push(p->queue, &task));
}
This pattern can be used for handling server requests. As each request is independent, each one of them can generate a response at is own pace. The problem is that in case the requests take up too much time to serve, newer clients may not have a response for a long period of time. That is what can be avoided using a green threads pattern, similar to the one provided by goroutines in Go. In that case, the runtime scheduler can reschedule the execution of goroutines, so none of them keeps waiting too much.
In the case of client code, we can use this pattern for executing tasks asynchronously. However, the limitation of this pattern is that in case several asynchronous tasks generate output for the client, as they are running independently without any synchronization we can end up having overlapping outputs coming out from multiple worker threads.
For example, let's write an example program that uses this thread pool to simulate several asynchronous calls that write their output into the console.
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <unistd.h>
#include <pthread.h>
#include <time.h>
#include "pool.h"
void download_img(void* data) {
printf("[%lu] BEGIN download_img", pthread_self());
sleep(1);
int r = rand();
printf("%d ", r);
printf("[%lu] END download_img\n", pthread_self());
}
void say_hello() {
printf("[%lu] Hello\n", pthread_self());
}
int main() {
srand(time(NULL));
ThreadPool* pool = new_ThreadPool();
{
char* line = NULL;
size_t len = 0;
ssize_t read;
while ((read = getline(&line, &len, stdin)) != -1) {
if (read>2 && strncmp("quit", line, read-1) == 0) {
break;
} else if (read>2 && strncmp("hello", line, read-1) == 0) {
say_hello();
} else if (read>2 && strncmp("download", line, read-1) == 0) {
for (int i=0; i<5; ++i) {
ThreadPool_submit(pool, (Task){
.cb = download_img,
.data = NULL
});
}
}
}
if (line != NULL) {
free(line);
}
}
delete_ThreadPool(pool);
return 0;
}
As there is no synchronization between the worker threads execution, their output can overlap each other. So multiple executions of the download command may have different outputs.
>clang -g -Iinclude cmd/main.c src/** -o bin/main -lpthread
>bin/main
download
[140364231157504] BEGIN download_img[140364247942912] BEGIN download_img[140364239550208] BEGIN download_img[140364256335616] BEGIN download_img1677218124 [140364256335616] END download_img
[140364256335616] BEGIN download_img1290723833 [140364239550208] END download_img
1311847477 [140364247942912] END download_img
1998703620 [140364231157504] END download_img
1256452635 [140364256335616] END download_img
download
[140364256335616] BEGIN download_img[140364239550208] BEGIN download_img[140364247942912] BEGIN download_img[140364231157504] BEGIN download_img649066008 448770898 1852008977 [140364256335616] END download_img[140364256335616] BEGIN download_img[140364247942912] END download_img
501791773 [140364239550208] END download_img
[140364231157504] END download_img
1564908724 [140364256335616] END download_img
In order to avoid race conditions in the output generated by asynchronous tasks, we need to use the next piece of our async/await puzzle, event loops. We'll cover that in the next part of this series.